More Agents Is All You Need
I read this fascinating paper titled “More Agents Is All You Need” and, it’s in line with the ensembling techniques from the classical machine learning techniques.
Key observations
So, what’s the big deal with adding more agents to LLM inference? According to the paper, it can improve the accuracy of the output in comparison to single instance of the LLM. For instance, An ensemble size of 20 Llama2-13B reached the accuracy of Llama2-70B and 15 Llama2-70B reached that of GPT-3.5.
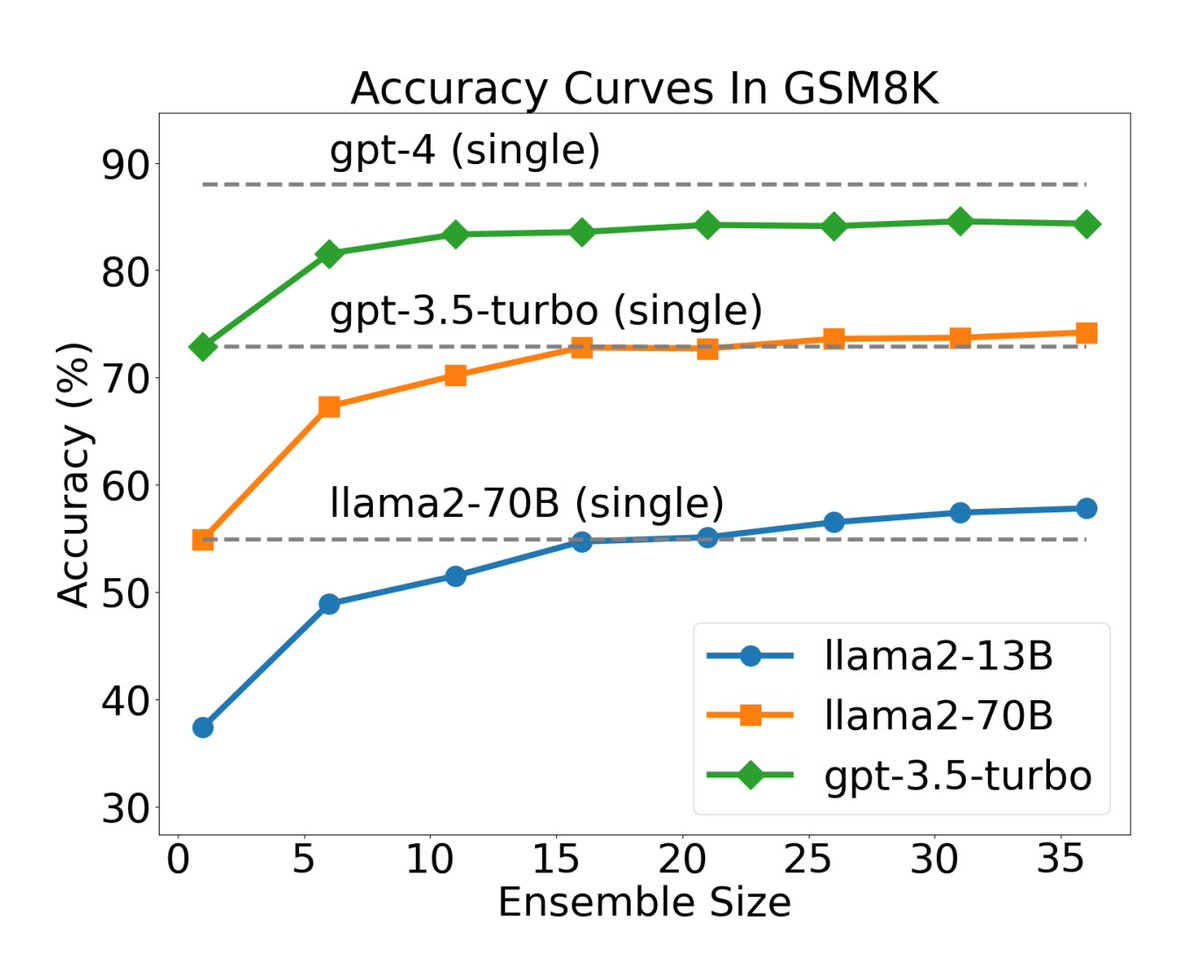
The logic applied by the authors is pretty simple, they improved the LLM performance by brute-force increasing the number of agents, without requiring complicated prompting techniques or complex collaboration frameworks.
Proposed Method
The method these researchers used is pretty straightforward. There are 2 phase to the solution:
- Input to LLM is iteratively fed into a single LLM or multiple LLM agents are fed in the same input to generate multiple output.
- The majority vote determines the final output.
Comparison to Contemporary Techniques
I found the comparison with other ensembling techniques particularly interesting:
- LLM Self-Ensemble: They using diverse CoT prompting to obtain variety in reasoning from a single LLM + voting, which makes them good for reasoning and compatible with CoT vs the proposed method provides good Reasoning + Generation and compatible with wider range of methods.
- Heterogeneous LLM Ensemble: This is a supervised LLM fusion framework to distill multiple models into one. It requires supervised learning, task specific data is needed and not generalised vs No such constrains in the proposed method.
- Multiple LLM Agents Collaboration: This focuses on the interactions between multiple LLM to enhance reasoning and task-solving capabilities, vs focusing on simply increasing the number of agents.
Understanding the Efficacy
To understand the efficacy of the solution, 3 orthogonal dimensions of task difficulty were considered:
- Inherent Difficulty: The complexity of the task itself.
- Number of Steps: More steps implies a more difficult task.
- Prior Probability: Result space partitioned into K equal probability intervals, then 1/K is is the Prior probability of the correct answer. Less prior probability implies more difficult task.
The relative performance increase of more agents with respect to single LLM query was defined as the Gain, and following observations were made.
- Gains increase then decrease by rising the inherent difficulty, owing to the limitations in the reasoning capabilities of the LLMs.
-
- Gains increase with the number of steps.
- Sampling-and-voting increases the performance for each step; applying sampling and voting compensates for the accumulation of errors from each step.
- The performance increases with the prior probability. Thus decomposing low-probability tasks into multiple high-probability subtasks and addressing them hierarchically can boost performance
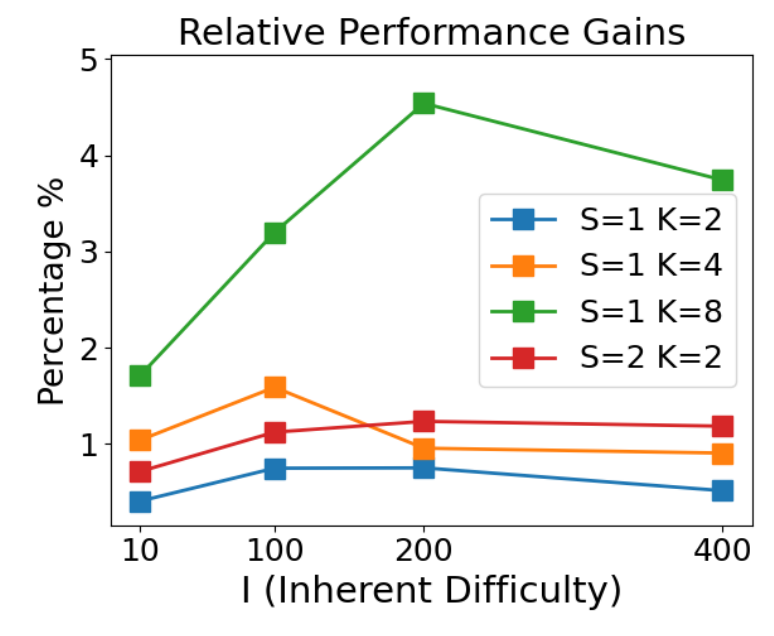
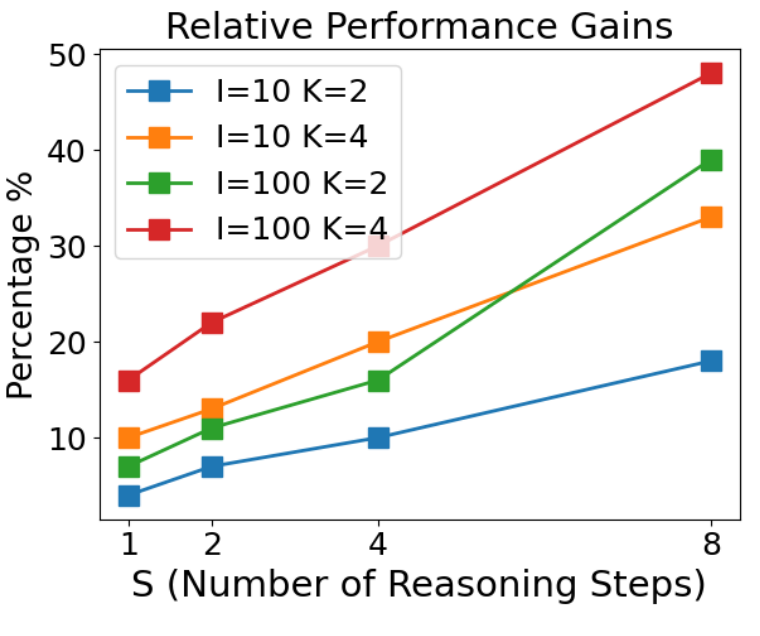
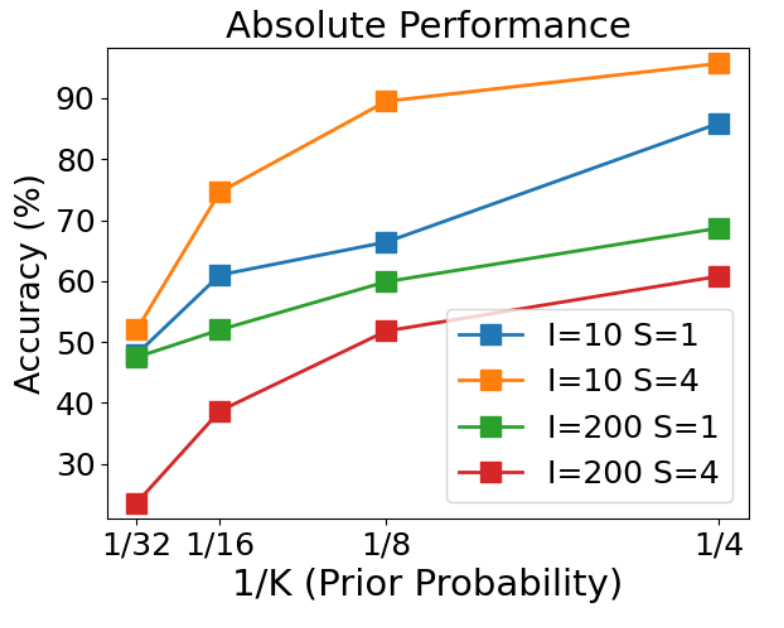
Conclusion
More agents is all you need, simple sampling-and-voting method for instantiating agents can generally improve the performance of LLMs by increasing the ensemble size, this can be combined with other existing techniques to further improve performance.
Here is my tweet thread.