We hear a lot about tokens in AI these days, in the form of “ChatGPT tokens”, “OpenAI tokens” when discussing models like ChatGPT, BERT, and other Large Language Models (LLMs). But what exactly are tokens, and why are they so pivotal in Natural Language Processing (NLP)?
Its all about Transformers
Transformers are a revolutionary architecture in NLP. The attention mechanism intrinsic to the Transformer architecture lets models focus on different parts of an input text with varied intensities. When scaled to unprecedented sizes and trained with vast data, these models demonstrate an uncanny ability to generate human-like text. In essence, it’s this Transformer architecture that has facilitated the birth and rise of models like ChatGPT.
A Glimpse into Transformers
Transformer models, such as those used in ChatGPT, have components like encoders and decoders. These elements enable the model to “transform” an input sequence of tokens into an output sequence. A special capability, known as self-attention, lets these models process an entire sequence of tokens collectively. This simultaneous processing aids in understanding context-dependent relationships between tokens.
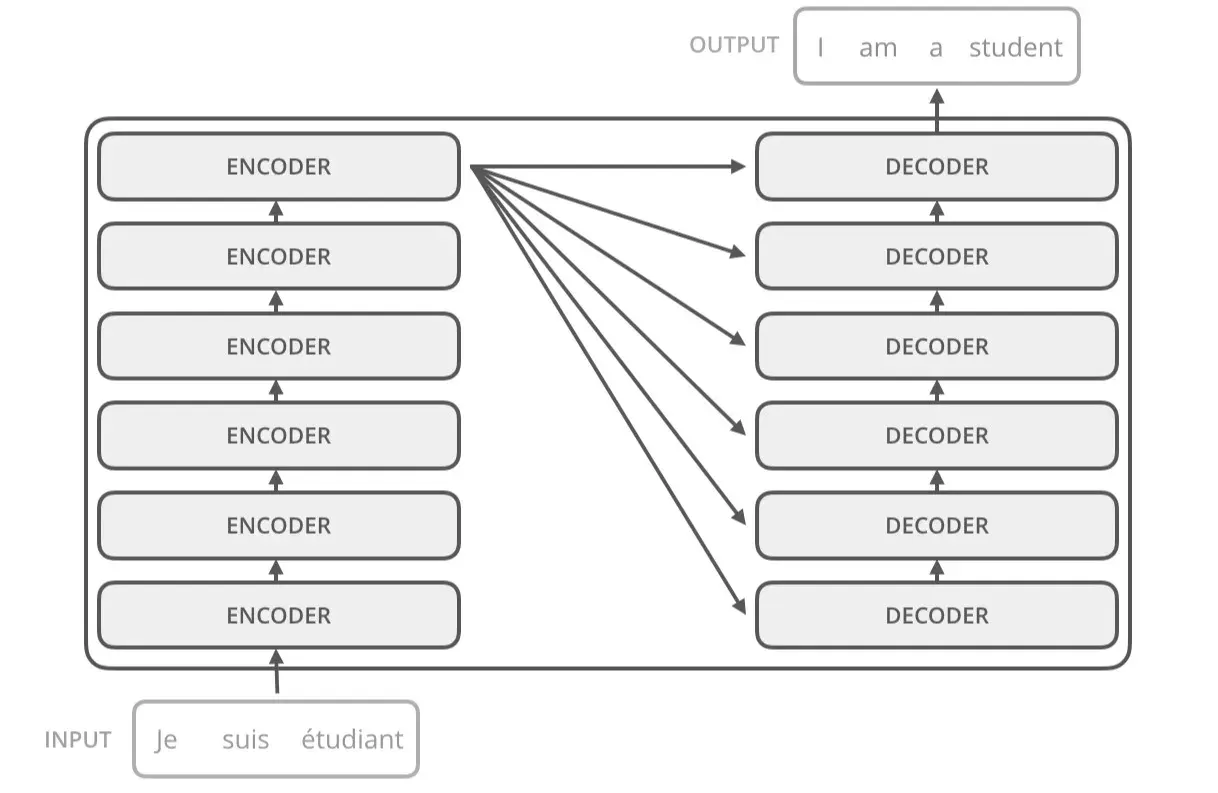
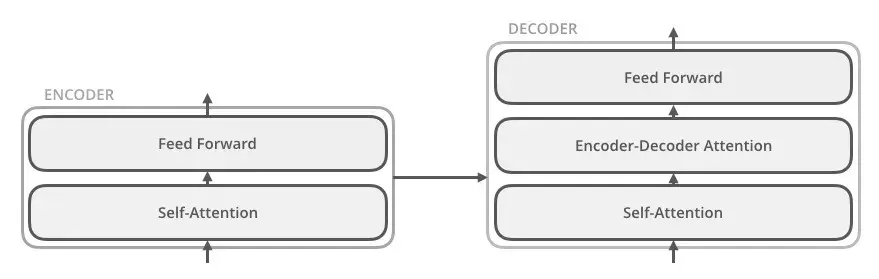
So, What Are Tokens?
In the simplest terms, a token is a representation of a word, a subword unit, or even just a character in machine learning. Consider the statement, “ChatGPT is innovative.” It could be broken down into tokens like [“ChatGPT”, “is”, “innovative”, ”.”] and “It didn’t rain today” could be broken to [“It”, “didn”, ”’”, “t”, “rain”, “today”]. Tokens can represent whole words, prefixes, suffixes, or just spaces and punctuation. They’re essentially the building blocks that models like ChatGPT utilize to analyze and produce language.
Significance of Tokens
Tokens hold paramount importance for several reasons:
-
Processing and Generation: LLMs like ChatGPT intake sequences of tokens as input and output tokens in response. They predict subsequent tokens based on patterns previously learned during training.
-
Efficiency and Context: Tokens aid in breaking down extensive text into comprehensible units, allowing the model to concentrate on the significance of individual tokens and, by extension, maintain context in conversations.
-
Model Capacity: Models have a token limit. For instance, ChatGPT-3.5 currently has a maximum token limit of 4096. This limitation marks the boundary for the amount of text you can process in given set of interaction with the model.
-
Cost Implications: Especially in cloud-based environments, the number of tokens in an interaction (input & output) directly impacts costs.
I made an app to list various model prices from multiple providers, here.
The Future
Different languages tokenize differently. For example, while English is space-delineated, languages like Chinese aren’t. This demands sophisticated tokenizing techniques. Additionally, token limitations sometimes necessitate truncating large texts, potentially affecting the conveyed context.
As technology advances, the way LLMs and Transformers handle tokens will evolve. With research steered toward improved token management, there’s much to look forward to, especially as models become increasingly multilingual and multimodal.
Conclusion
Tokens, the foundational units in models like ChatGPT, Claude, Llama and other LLMs, are integral to our understanding and utilization of these state-of-the-art models. As AI continues to advance, our grasp of such underlying mechanics will be pivotal in harnessing their full potential.